|
以我们提出的M算法与挖掘关联规则的权威算法Apriori算法做一典型的对比分析。
1) 基于的学术思想不同:M算法是基于双库协同机制的内在认知机理研究,具体而论是基于“知识短缺”(利用有向超图)进行“定向挖掘”以及知识库的实时维护;而Apriori算法是基于组合论的数据库全局搜索。
2) 基本流程(或基于的结构模型)不同:M算法是一条一条短缺知识的挖掘;而Apriori算法是所有的规则一并挖掘。
3) 基础不同:M算法是基于规则强度,它考虑了主观和客观两个方面;涵盖了Apriori算法的支持度阈值。
4) 发现知识的量不同:在M算法中知识库直接参与挖掘过程,从而能真正发现新颖的、用户感兴趣的知识,这正是符合了KDD定义;而Apriori算法是把满足条件的规则全部挖掘出来;另外,由于M算法中的支持度可以设置的比较小(因为该算法主要是由规则强度来聚焦的),即对短缺知识的删除是比较谨慎的, 因此M算法部分地克服了Apriori算法的一个缺陷——遗漏重要规则。
5) M算法可融入KDD中形成新的开放型的结构模型——KDD*,整个算法实现的运算背景是KDD*结构;而Apriori算法是原有的KDD系统。
2.3.2 源于DFSSM的Web文本分类的TCDFSSM算法
源于DFSSM的Web文本分类算法TCDFSSM的算法流程如图12所示。该项内容已获国家发明专利《一种Web挖掘系统的构造方法》(ZL 03104960.5)(见附件 )
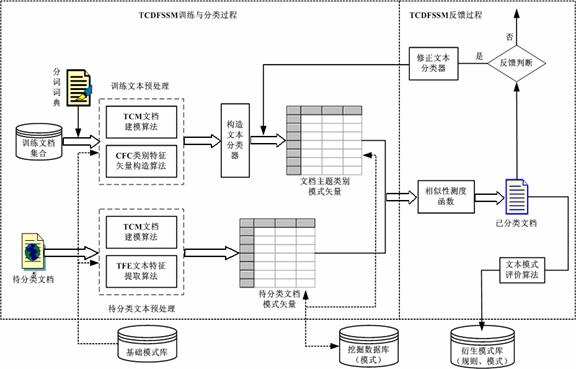
图12 TCDFSSM文本分类算法流程图
该算法与现有文献中的文本分类算法有很大差异,我们通过实验验证了它的优势。
表2 三类文本分类算法的时间复杂度比较表
|
算法名称 |
训练阶段时间复杂度 |
分类阶段时间复杂度 |
|
TCDFSSM |
O(mn) |
O(cn) |
|
朴素贝叶斯 |
O(mn) |
O(cn) |
|
KNN |
无 |
O(cn+mn) |
表3 三类文本分类算法的综合分类率(F1值)的实验对比结果表
|
算法名称 |
语料库1的F1值(%) |
语料库2的F1值(%) |
|
封闭 |
开放 |
封闭 |
开放 |
|
TCDFSSM |
95.5 |
93.5 |
93.6 |
91.1 |
|
朴素贝叶斯 |
91.3 |
90.6 |
89.2 |
88.5 |
|
KNN |
93.7 |
91.7 |
92.3 |
90.8 |
表4为三类分类算法的运行时间分析表。运行时间示意图如图13所示。
表4 三种分类算法运行时间分析表
|
文档数(篇) |
100 |
400 |
600 |
1000 |
|
TCDFSSM算法运行时间(s) |
15 |
25 |
50 |
100 |
|
朴素贝叶斯算法运行时间(s) |
45 |
76 |
135 |
254 |
|
KNN算法运行时间(s) |
90 |
217 |
413 |
927 |
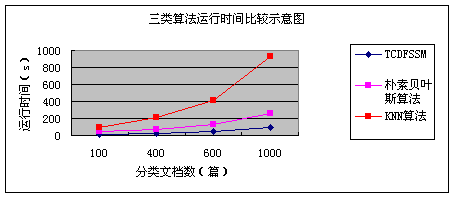
图13 三类分类算法运行时间比较示意图
上一页 [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] 下一页
|