2.2.1 KDD*过程模型
基于双库协同机制的KDD*结构模型用于处理结构化数据挖掘问题,它区别于固有的KDD模型。在论证了数据子类结构的可达范畴与挖掘知识库的推理范畴之间的等价关系的基础上,它通过启发型协调器从知识库中发现知识短缺,启动挖掘进程使机器自身主动聚焦,得到假设规则;并通过维护型协调器实时地到知识库中对应位置查找重复、冗余、矛盾等情况进行知识库的实时维护。该项内容已获国家发明专利《一种基于双库协同机制的KDD*方法及系统》(ZL 01145080.0)(见附件 )。
下面通过KDD*结构模型与经典的KDD结构模型的对比做典型说明:
KDD结构模型旨在为KDD提供宏观指导和工程化方法。目前,国内外学者已提出了若干模型,如Brachman等于1996年提出一种实用的KDD过程视图,该视图强调的是过程的交互性;NCR、SPSS、DaimlerChrysler和OHRA于1997年开始了KDD结构模型工业标准的制定工作,并在1999年推出了CRISP-DM的KDD结构模型工业标准的1.0版。这其中,Fayyad等提出的多阶段模型以其通用性而被广泛接受。这一模型如图4所示:
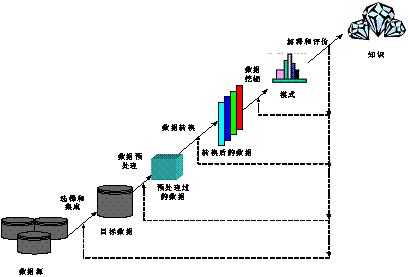
图4 Fayyad等提出的经典的KDD结构模型
基于双库协同原理(机制),我们提出了全新的KDD*结构模型,其总体结构如图5所示:
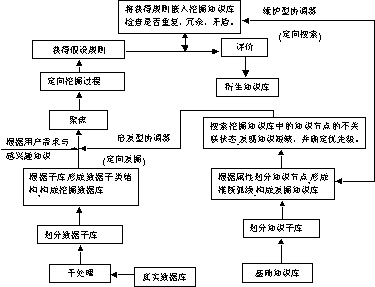
图5 KDD*系统总体结构图
与Fayyad等提出的结构模型相比,KDD*有如下特征:
1) KDD*有机地沟通与融合了KDD*新发现的知识与基础知识库中固有的知识,使它们成为一个有机的整体;即实现了“用户的先验知识与先前发现的知识可以耦合到发现过程中”。
2) 在知识发现过程中,KDD*对于冗余性的、重复性的、不相容的信息做出了实时处理(即知识库的实时维护),有效地减少了由于过程积累而造成的问题的复杂性,同时为新旧知识的融合与合成提供了先决条件;实现了“知识与数据库同步进化”。
3) KDD*改变与优化了知识发现的过程与运行机制,实现了“多源头”聚焦与减少评价量。
4) KDD*强化了知识发现的智能化程度,提高了认知自主性(这将是今后相当长的一阶段内保持的研究基调),较有效地克服领域专家的自身局限性,实现了“采用领域知识辅助初始发现的聚焦”。
5) 作为KDD*的核心技术―双库协同机制的研究,揭示了在知识发现过程中,在一定的建库原则下,知识库与数据库间的对应关系;为实现“限制性的搜索”而减小搜索空间、提高发掘效率提供了有效的技术方法。
上一页 [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] 下一页
|