|
3) 关于双库协同机制具体实现的进一步讨论。例如:可达关系的概率估计定理:设p>2a+a2/(1-a);对定义的参数b和B, 令a<b<(1-a)p, 令(1-p+pa)/(1-a)<B<1-a. 则随着论域X的数据库Â(X)中元组数目S(R)的增加,本原知识库中每一条正规则对应的数据子类结构库中的关系为一个可达关系的概率均趋于1;每一条反规则对应的关系为非可达关系的概率均趋于1。
1.2.2双基融合机制 (两个知识发现过程间的内在联系)
双库协同机制给出了特定结构下数据库与知识库的对应关系,那么基于数据库的KDD与基于知识库的KDK的两个发现过程有无内在联系呢?我们得到了肯定的回答。
我们发现了表面上毫无关联的两个知识发现过程(KDD与KDK)的内在联系;双基融合机制将两者统一在一个知识发现系统(过程)中,使其相辅相成,是一种机器智能的较高境界。设计了R型协调器、S型协调器与T型协调器,解决了KDK依赖与部分地转化为KDD的难题。该项内容已正式申报国家发明专利《一种融入R型协调器的KDK系统》(200510086965.8)、《一种融入R型与S型协调器的KDK系统》(200510086964.3)和《一种基于双基融合机制的的KDK*系统》(200510086966.2)(见附件 )。
1)(KDD与KDK)过程模型逻辑等价定理:设KDK的过程模型为M=,KDD的过程模型为N =,在依数据子类结构构建数据库,依知识结点网络构建知识库的条件下,M与N各要素间建立了一一对应关系,即M与N逻辑等价。其中:Q为结点集,R为认知通达关系,f为正则测度函数,g为正则确信度函数;S为数据子类集,F为可达性关系,Sup为数据子类的支持度,Vel为F上的挖掘可信度。
依据该定理,我们可将部分KDK挖掘问题转化为KDD的挖掘问题;同时为规则验证提供了转换的根据。
2) 双基融合机制的实现:构造了R型、S型、T型三个协调器,并设计了相应的软件。
1.2.3信息扩张机制 (动态挖掘进程规律)
目前的挖掘算法与评价方法的讨论基本上是在一个时间剖面上,相对稳定的状态下进行的,而对于动态挖掘进程、实时与在线的挖掘进程考虑得较少;扩散、演化与预测性研究日趋重要。信息扩张机制主要指当数据挖掘过程从一个抽象级向下一个抽象级、从固有数据库(知识库)向扩展数据库(知识库)过渡的时候,所呈现的运行规律。如:规则价值的动态评价、类似于"不动点"的数据簇的寻求、"突变"协调算法、基于知识信息熵的预览算法、数据挖掘复杂性研究等问题。得到的主要结果如下:
1) 动态挖掘进程中规则参数的演化规律的研究:
基于认知物理学的“语言场”与“信息扩散原理”,发现了关联规则的特类――意外规则参数演化的规律;
参数演化定理:在KDD的动态挖掘进程中的某一时间段内,在对实时数据库DB实施分库和每种参数只考虑上升、平行、下降三种演化情况的前提下,对于意外规则而言,其组.态空间可划归为S={<0,0,0,0,0>, <0,0,0,1,-1>, <0,0,0,-1,1>, <-1,0,-1,0,0>, <-1,0,-1,1,-1>, <-1,0,-1,-1,1>, <0,1,-1,0,1>, <0,1,-1,-1,1>, <0,1,-1,1,0>, <0,1,-1,1,1>, <0,1,-1,1,-1>, <-1,1,-1,0,1>, <-1,1,-1,-1,1>, <-1,1,-1,1,0>, <-1,1,-1,1,1>, <-1,1,-1,1,-1>}。
该定理将1024种参数演化的组态情况化归为16种(波动型除外,对于波动型利用“信息扩散原理”加以讨论),并给出了被认为是知识发现难点的可理解性讨论的5类主题分析。
对于波动型的讨论:规则的参数波动变化的情况有781种,对参数波动变化的态势可采用下述的方法处理----信息扩散原理是一种在样本不足的情况下,对样本应遵循的规律进行认识的模糊数据处理方法。我们提出的自动评价方法可在领域专家不介入的情况下,利用知识(规则)的可计算参数进行评价;并由信息扩散原理弥补参数相对不足的缺陷,得到规则参数的概率分布信息,据此客观地展现规则特征,从而实现规则评价。
2) 矛盾域分布的研究:
定义 设在对真实数据库的动态挖掘时,规则的两个参数(支持度和可信度)的阈值
设为 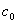 和 和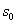 若下列两参数联立不等式: 若下列两参数联立不等式:
① 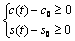 ② ②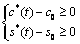
有解。则称所求 的区间(或点集)为矛盾域。其中 的区间(或点集)为矛盾域。其中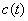 、 、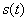 为三维空间中规则两参数对 为三维空间中规则两参数对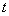 的函数。 的函数。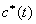 、 、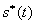 为对应矛盾规则(满足矛盾规则概念模型)对的函数。 为对应矛盾规则(满足矛盾规则概念模型)对的函数。
定理 研究数据挖掘中矛盾规则的问题,可以抽象为在一个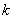 维向量空间 维向量空间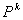 中,求解规则(比如产生式规则P→Q)与其对应的受矛盾规则概念模型约束的矛盾规则(P→┒Q)的参数向量同时落在阈值空间 中,求解规则(比如产生式规则P→Q)与其对应的受矛盾规则概念模型约束的矛盾规则(P→┒Q)的参数向量同时落在阈值空间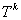 中的问题。 中的问题。
3) 变论域下阈值设置的研究:
一般方法是先在数据属性论域中,讨论实际数据库中数据项目属性的特征,进行模
糊综合评判,确定各个项目客观合理的最小支持度阈值(为“点值”类阈值);然后在时空论域中,从数据库本身的动态变化中寻找变化规律,使用阈值协调器计算规则的基础的阈值取值区间;最后确定变论域下阈值设置的输出函数( 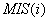 )。用户只需依照该阈值设置函数对阈值进行设置,将可以达到我们客观合理地设置阈值的目的确。 )。用户只需依照该阈值设置函数对阈值进行设置,将可以达到我们客观合理地设置阈值的目的确。
4) 知识发现系统中信息熵方法的应用研究:
理论物理研究的成果表明,热力学熵适合于研究海量粒子的分布规律。现代信息论在通讯等领域的成功应用表明,信息熵适用于研究人们有效获取知识或信息的方法。
定理:如果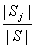 表示任何一个元素在 表示任何一个元素在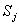 中出现的概率, 中出现的概率,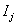 是对中的任何一个元 是对中的任何一个元
素分类所需要的平均信息量,则对样本空间中任一个元素分类所需要的信息量为:
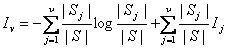
这个结论比ID3算法的理论分析结果多出了一项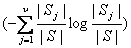 。 。
此可克服ID3算法倾向于属性值较多的属性的缺陷。
信息熵一般表达式:我们应用所建立的关于概念及其分解的符号体系得到了树形概念分解之下,基于任何概念粒度的信息熵(信息蕴含量)的一般表达式
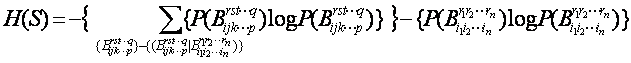 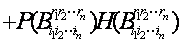
上一页 [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] 下一页
|